VarName 发布:把“变量怎么命名”这件事交给工具
VarName(变量命名工具)现已正式上线:https://varname.letoy.xyz/。
写代码时,“命名”往往不是能力问题,而是成本问题:同样一句业务意图,有的人能迅速落到一个清晰、符合规范的变量名;更多时候我们会在语义、习惯、风格之间反复权衡——既担心名字不准确,又怕它看起来“不专业”。这类犹豫会在高频的小决策里不断累积,最终拖慢编码节奏。
VarName 的定位很明确:把变量命名从“凭感觉翻译”提升为“有工程语境支撑的命名建议”。它不是简单的中英转换,也不是只靠词库拼装,而是尽量让每一个建议都能解释得通、用得安心。
目前 VarName 已累计收录并学习了 45 万条优质变量命名,并将这些真实工程样本作为命名建议的参考基础。你可以输入自然语言描述或中文词汇,系统会给出多组候选命名,并附带简短理由与标签提示;同时支持多种命名风格的转换与一键复制,直接用于代码、配置与接口相关命名场景。
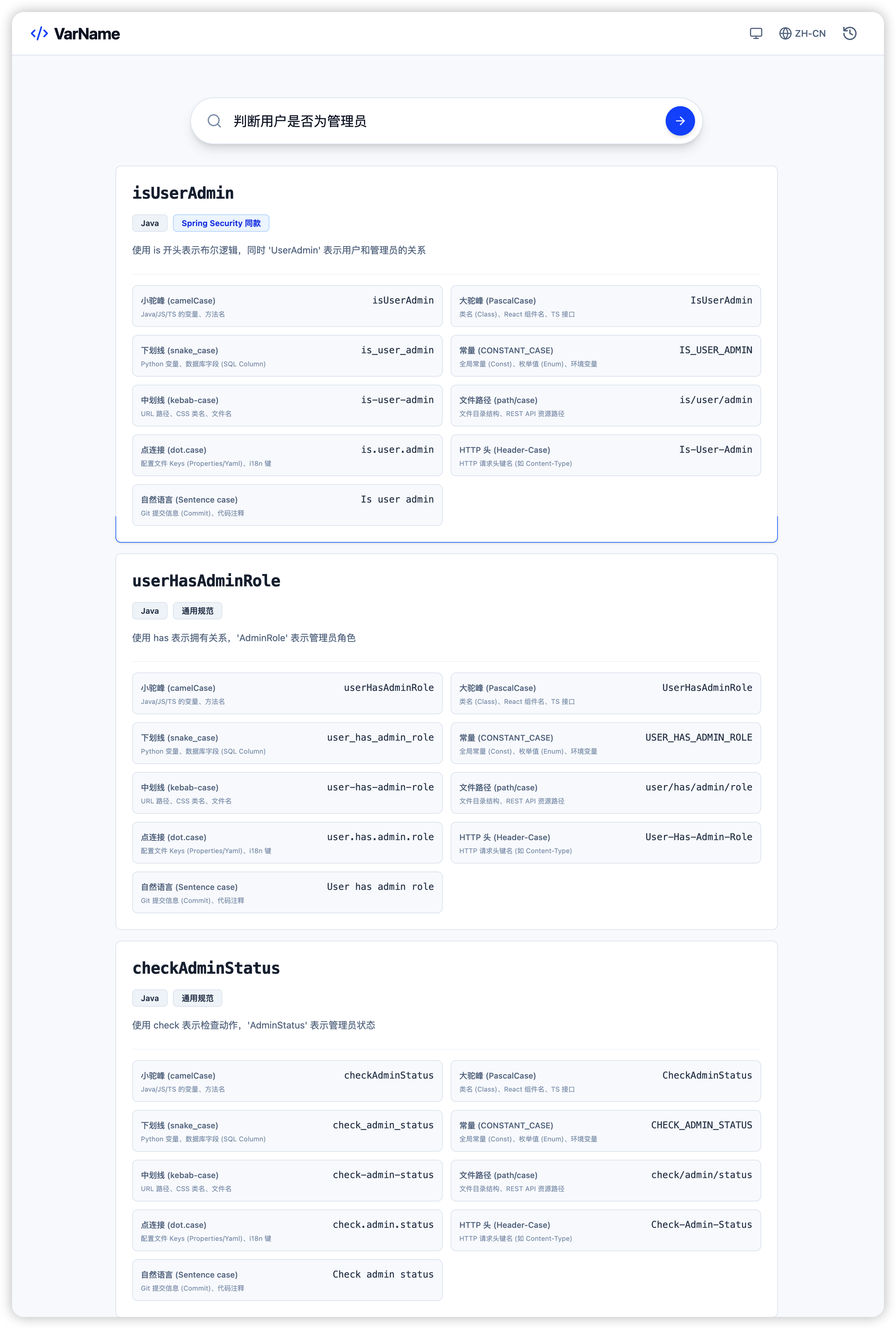
从页面示例(“判断用户是否为管理员”)可以看到,VarName 会给出不同侧重点的表达:例如 isUserAdmin 更符合布尔判断型变量的直觉与惯例userHasAdminRole 更强调“拥有角色”的关系语义checkAdminStatus 则更偏向“检查动作 + 状态对象”的表达方式。它们并非同义反复,而是在工程里常见的几种命名路径。VarName 想做的不是替你拍板,而是把差异和理由呈现清楚,让你在几秒钟内做出更稳妥的选择。
很多人对 AI 命名工具的疑虑,核心在于两点:一是“会不会瞎编一个看起来很像的名字”,二是“凭什么相信它符合工程规范”。VarName 的实现逻辑就是围绕这两点设计的:先用检索把建议锚定在真实工程语境里,再由模型做语义推理与表达选择,尽量减少“无依据生成”的不确定性。
VarName 的技术方案是前端 React,后端 Spring Boot,并由 Spring AI 驱动 GLM-4 完成推理;在生成之前,系统会先进行检索增强(RAG)。当你提交描述后,请求会先查询 Redis 缓存;未命中时,后端会在 PostgreSQL(启用 pgvector)中的知识库里做向量检索,找出与输入意图相近的参考样本(这些样本来自离线的 Python 管道对优质 GitHub 仓库的抓取与清洗)。检索得到的参考上下文会与用户输入一起组成提示词,再交给 GLM-4 生成结构化的候选结果(命名、标签、理由)。为了不影响主链路响应,历史记录会以异步方式写入数据库,同时结果会写回 Redis,以便后续复用与加速。简单概括就是:**先“找依据”,再“做推理”,最后“给解释”**——这也是 VarName 用来保证命名专业性与可用性的关键路径。
在体验上,VarName 采用无感的 UUID 机制:不需要注册或登录;前端首次访问生成 UUID 并保存在本地,后续请求通过 X-User-UUID 传递,用于关联你的历史记录与收藏。隐私与数据方面,VarName 只会按照 UUID 关联保存记录。
目前 VarName 免费使用,欢迎提出问题与建议。项目计划后续开源,并会上线常用开发工具插件,但目前仍在策划中,时间未定。现阶段我更希望先把命名建议的质量打磨扎实:更贴近真实工程语境、更符合主流规范、更能解释清楚“为什么是这个名字”。如果你在使用中遇到建议不贴合语义、希望支持更明确的命名偏好/团队规范,或对标签与理由有改进意见,都欢迎反馈,我会基于真实使用场景持续迭代。